The “gap between the hardware and the software of a concrete computer and even greater gap between pure functioning of the computer and its utilization by a user, demands description of many other operations that lie beyond the scope of a computer program, but might be represented by a technology of computer functioning and utilization”
Marc S. Burgin, “Super Recursive Algorithms”, Springer, New York, 2005
Introduction
According to Holbrook (Holbrook 2003), “Specifically, creativity in all areas seems to follow a sort of dialectic in which some structure (a thesis or configuration) gives way to a departure (an antithesis or deviation) that is followed, in turn, by a reconciliation (a synthesis or integration that becomes the basis for further development of the dialectic). In the case of jazz, the structure would include the melodic contour of a piece, its harmonic pattern, or its meter…. The departure would consist of melodic variations, harmonic substitutions, or rhythmic liberties…. The reconciliation depends on the way that the musical departures or violations of expectations are integrated into an emergent structure that resolves deviation into a new regularity, chaos into a new order, surprise into a new pattern as the performance progresses.”
Current IT in this Jazz metaphor, evolved from a thesis and currently is experiencing an anti-thesis and is ripe for a synthesis that would blend the old and the new with a harmonious melody to create a new generation of highly scalable, distributed, secure services with desired availability, cost and performance characteristics to meet the changing business priorities, highly fluctuating workloads and latency constraints.
The Hardware Upheaval and the Software Shortfall
There are three major factors driving the datacenter traffic and their patterns:
1. A multi-tier architecture which determines the availability, reliability, performance, security and cost of initiating a user transaction to an end-point and delivering that service transaction to the user. The composition and management of the service transaction involves both the north-south traffic from end-user to the end-point (most often over the Internet) and the east-west traffic that flows through various service components such as DMZ servers, web servers, application servers and databases. Most often these components exist within the datacenter or connected through a WAN to other datacenters. Figure 1 shows a typical configuration.

Service Transaction Delivery Network
The transformation from the client-server architectures to “composed service” model along with virtualization of servers allowing the mobility of Virtual Machines at run-time are introducing new patterns of traffic that increase in the east west direction inside the datacenter by orders of magnitude compared to the north-south traffic going from end-user to the service end-point or vice-versa. Traditional applications that evolved from client-server architectures use TCP/IP for all the traffic that goes across servers. While some optimizations attempt to improve performance for applications that go across servers using high-speed network technologies such as InfiniBand, Ethernet etc., TCP/IP and socket communications still dominate even among virtual servers within the same physical server.
2. The advent of many-core severs with tens and even hundreds of computing cores with high bandwidth communication among them drastically alters the traffic patterns. When two applications are using two cores within a processor, the communication among them is not very efficient if it uses socket communication and TCP/IP protocol instead of shared memory. When the two applications are running in two processors within the same server, it is more efficient to use PCIExpress or other high-speed bus protocols instead of socket communication using TCP/IP. If the two applications are running in two servers within the same datacenter it is more efficient to use Ethernet or InfiniBand. With the advent of mobility of applications using containers or even Virtual Machines, it is more efficient to switch the communication mechanism based on the context of where they are running. This context sensitive switching is a better alternative to replicating current VLAN and socket communications inside the many-core server. It is important to recognize that the many-core servers and processors constitute a network where each node itself is a sub-network with different bandwidths and protocols (socket-based low-bandwidth communication between servers, InfiniBand, or PCI Express bus based communication across processors in the same server and shared memory based low latency communication across the cores inside the processor). Figure 2 shows the network of networks using many-core processors.
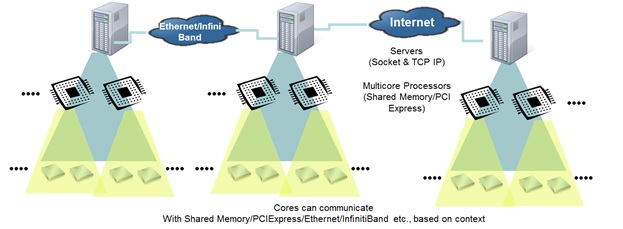
A Network of Networks with Multiple Protocols
3. The many-core servers with new class of flash memory and high-bandwidth networks offer a new architecture for services creation, delivery and assurance going far beyond the current infrastructure-centric service management systems that have evolved from single-CPU and low-bandwidth origins. Figure 3 shows a potential architecture where many-core servers are connected with high-bandwidth networks that obviate the need for current complex web of infrastructure technologies and their management systems. The many-core servers each with huge solid-state Drives, SAS attached inexpensive disks, optical switching interfaces connected to WAN Routers offer a new class of services architecture if only the current software shortfall is plugged to match the hardware advances in server, network and storage devices.

If Server is the Cloud, What is the Service Delivery Network?
This would eliminate the current complexity mainly involved in dealing with TCP/IP across east-west traffic and infrastructure based service delivery and management systems to assure availability, reliability, performance, cost and security. For example, current security mechanisms that have evolved from TCP/IP communications do not make sense across east/west traffic and emerging container based architectures with layer 7 switching and routing independent of server and network security offer new efficiencies and security compliance.
Current evolution of commodity clouds and distributed virtual datacenters while providing on-demand resource provisioning, auto-failover, auto-scaling and live-migration of Virtual machines, they are still tied to the IP address and associated complexity of dealing with infrastructure management in distributed environments to assure the end-to-end service transaction quality of service (QoS).
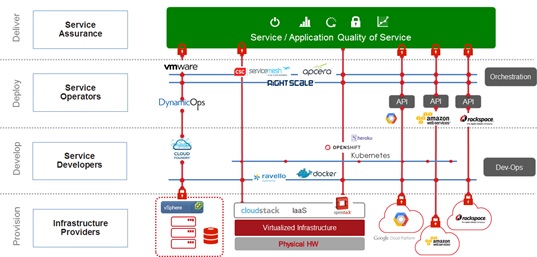
The QoS Gap
This introduces either vendor lock-in that precludes the advantages of commodity hardware or introduces complexity in dealing with multitude of distributed infrastructures and their management to tune the service transaction QoS. Figure 4 shows the current state of the art. One can quibble whether it includes every product available or whether they are depicted correctly to represent their functionality but the general picture describes the complexity and or vendor lock-in dilemma. The important point to recognize is that the service transaction QoS depends on tuning the SLAs of distributed resources at run-time across multiple infrastructure owners with disparate management systems and incentives. The QoS tuning of service transactions is not scalable without increasing cost and complexity if it depends on tuning the distributed infrastructure with a multitude of point solutions and myriad infrastructure management systems..
What the Enterprise IT Wants:
There are three business drivers that are at the heart of the Enterprise Quest for an IT framework:
- Compression of Time-to-Market: Proliferation of mobile applications, social networking, and web-based communication, collaboration and commerce are increasing the pressure on enterprise IT to support a rapid service development, deployment and management processes. Consumer facing services are demanding quick response to rapidly changing workloads and the large-scale computing, network and storage infrastructure supporting service delivery requires rapid reconfiguration to meet the fluctuations in workloads and infrastructure reliability, availability, performance and security.
- Compression of Time-to-Fix: With consumers demanding “always-on” services supporting choice, mobility and collaboration, the availability, performance and security of end to end service transaction is at a premium and IT is under great pressure to respond by compressing the time to fix the “service” regardless of which infrastructure is at fault. In essence, the business is demanding the deployment of reliable services on not so reliable distributed infrastructure.
- Cost Reduction of IT operation and management which is running at about 60% to 70% of its budget going to keep the “service lights” on: Current service administration and management paradigm that originated with server-centric and low-bandwidth network architecture is resource-centric and assumes that the resources (CPU, memory, network bandwidth, latency, storage capacity, throughput and IOPs) allocated to an application at install time can be changed to meet rapidly changing workloads and business priorities in real-time. Current state-of-the art uses virtual servers, network and storage that can be dynamically provisioned using software API. Thus the application and service (a group of applications providing a service transaction) QoS (quality of service defining the availability, performance, security and cost) can be tuned by dynamically reconfiguring the infrastructure. There are three major issues with this approach:
With a heterogeneous, distributed and multi-vendor infrastructure, tuning the infrastructure requires myriad point solutions, tools and integration packages to monitor current utilization of the resources by the service components, correlate and reason to define the actions required and coordinate many distributed infrastructure management systems to reconfigure the resources.
In order to provide high availability and disaster recovery (HA/DR), recent attempts to move Virtual Machines (VM) introduces additional issues with IP mobility, Firewall reconfiguration, VM sprawl and associated run-away VM images, bandwidth and storage management.
Introduction of public clouds and the availability of software as a service, while they have worked well for new application development or non-mission critical applications or applications that can be re-architected to optimize for the Cloud API which leverage application/service components available, they are also adding additional cost for IT to migrate many existing mission critical applications that demand high security, performance and low-latency. The suggested Hybrid solutions require adopting new cloud architecture in the datacenters or use myriad orchestration packages that add additional complexity and tool fatigue.
In order to address the need to compress time to market and time to fix and to reduce the complexity, enterprises small and big are desperately looking for solutions.
The lines of business owners want:
- End-to-end visibility and control of service QoS independent of who provides the infrastructure
- Availability, performance and security governance based on policies
- Accounting of resource utilization and dynamic resolution of contention for resources
- Application architecture decoupled from infrastructure while still enabling continuous availability (or decouple functional requirements execution from non-functional requirement compliance)
IT wants to provide the application developers:
- Application architecture decoupled from infrastructure by separating functional and non-functional requirements so that the application developers focus on business functions while deployment and operations are adjusted at run-time based on business priorities, latency constraints and workload fluctuations
- Provide cloud-like services (on-demand provisioning of applications, self-repair, auto-scaling, live-migration and end-to-end security) at service level instead of at infrastructure level so that they can leverage own datacenter resources, or commodity resources abundant in public clouds without depending on cloud architectures, vendor API and cloud management systems.
- Provide a suite of applications as a service (databases, queues, web servers etc.)
- Service composition schemes that allow developers to reuse components and
- Instrumentation to monitor service component QoS parameters (independent from infrastructure QoS parameters) to implement policy compliance
- When problems occur provide component run-time QoS history to developers
IT wants to have the:
- Ability to use local infrastructure or on demand cloud or managed out-sourced infrastructure
- Ability to use secure cloud resources without cloud management API or cloud architecture dependence
- Ability to provide end to end service level security independent of server and network security deployed to manage distributed resources
- Ability to provide end-to-end service QoS visibility and control (on-demand service provisioning, auto-failover, auto-scaling, live migration and end-to-end security) across distributed physical or virtual servers in private or public infrastructure
- Ability to reduce complexity and eliminate point solutions and myriad tools to manage distributed private and public infrastructure
Application Developers want:
- To focus on developing service components, test them in their own environments and publish them in a service catalogue for reuse
- Ability to compose services, test and deploy in their own environments and publish then in the service catalogue ready to deploy anywhere
- Ability to specify the intent, context, constraints, communication, and control aspects of the service at run-time for managing non-functional requirements
- An infrastructure that uses the specification to manage the run-time QoS with on-demand service provisioning on appropriate infrastructure (a physical or virtual server with appropriate service level assurance, SLA), manage run-time policies for fail-over, auto-scaling, live-migration and end-to-end security to meet run-time changes in business priorities, workloads and latency constraints.
- Separation of run-time safety and survival of the service from sectionalizing, isolating, diagnosing and fixing at leisure
- Get run-time history of service component behavior and ability to conduct correlated analysis to identify problems when they occur.
We need to discover a path to bridge the current IT to the new IT without changing applications, or the OSs or the current infrastructure while providing a way to migrate to a new IT where service transaction QoS management is truly decoupled from myriad distributed infrastructure management systems. This is not going to happen with current ad-hoc programming approaches. We need a new or at least an improved theory of computing.
As Cockshott et al (2012) point out current computing, management and programming models fall short when you try to include computers and the computed in same model.
“the key property of general-purpose computer is that they are general purpose. We can use them to deterministically model any physical system, of which they are not themselves a part, to an arbitrary degree of accuracy. Their logical limits arise when we try to get them to model a part of the world that includes themselves.”
There are emerging technologies that might just provide the synthesis (reconciliation depends on the way that the architecture departures or violations of expectations are integrated into an emergent structure that resolves deviation into a new regularity, chaos into a new order, surprise into a new pattern as the transformation progresses) required to build the harmony by infusing cognition into computing. Only future will tell if this architecture is expressive enough and efficient as Mark Burgin claims in his elegant book on “Super Recursive Algorithms” quoted above.
Is the Information Technology poised for a renaissance (with a synthesis) since the great masters (Turing, von Neumann, Shannon etc.) developed the original thesis and take us beyond the current distributed-cloud-management anti-thesis.
The IEEE WETICE2015 International conference track on “the Convergence of Distributed Clouds, GRIDs and their Management” to be held in Cyprus next June (15 – 18) will address some of these emerging trends and attempt to bridge the old and the new.

24th IEEE International Conference on Enabling Technologies: Infrastructures for Collaborative Enterprises (WETICE2015) in Larnaca, Cyprus
For a state-of-the-emerging-science, please go to Infusing Self-Awareness into Turing Machine – A Path to Cognitive Distributed Computing presented in WETICE2014 in Parma Italy
References:
Holbrook, Morris B. 2003. ” Adventures in Complexity: An Essay on Dynamic Open Complex Adaptive Systems, Butterfly Effects, Self-Organizing Order, Coevolution, the Ecological Perspective, Fitness Landscapes, Market Spaces, Emergent Beauty at the Edge of Chaos, and All That Jazz.” Academy of Marketing Science Review [Online] 2003 (6) Available: http://www.amsreview.org/articles/holbrook06-2003.pdf
Cockshott P., MacKenzie L. M., and Michaelson, G, (2012) Computation and its Limits, Oxford University Press, Oxford.

Leave a comment